Facial recognition in web

This site is being translated
En este artículo, se mostrará el procedimiento para crear un sistema de inicio de sesión en entornos web utilizando Python y reconocimiento facial. Utilizaremos bibliotecas básicas, sin profundizar demasiado en el ámbito de la inteligencia artificial, ya que este tema se explorará en un próximo artículo.
Enlaces
Requisitos:
- Python 3
- pip
- virtualenv
- Node.js (versión v18.16.0 o superior)
- NPM (versión 9.5.1)
Ejecución
Front end
Vamos a crear un proyecto en html y javascript vanilla para este ejemplo
mkdir frontend
cd frontend
touch index.html style.css main.js<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link href="./style.css" type="text/css" rel="stylesheet" />
<title>Face login</title>
</head>
<body>
<video id="video" width="640" height="480" autoplay></video>
<button id="captureBtn">Iniciar sesión</button>
<div id="result">
<div id="login-message"></div>
<div id="login-data"></div>
</div>
<canvas
id="canvas"
width="640"
height="480"
style="display: none;"
></canvas>
<img id="capturedImage" src="" alt="Capturado" style="display: none;" />
<script src="./main.js" type="text/javascript"></script>
</body>
</html>// main.js
const video = document.getElementById("video");
const canvas = document.getElementById("canvas");
const capturedImage = document.getElementById("capturedImage");
const captureBtn = document.getElementById("captureBtn");
const loginMsg = document.getElementById("login-message");
const loginData = document.getElementById("login-data");
navigator.mediaDevices
.getUserMedia({ video: true })
.then(function (stream) {
video.srcObject = stream;
})
.catch(function (error) {
console.error("Error al acceder a la cámara: ", error);
});
captureBtn.addEventListener("click", function () {
canvas.getContext("2d").drawImage(video, 0, 0, canvas.width, canvas.height);
canvas.toBlob(function (blob) {
// Crear una nueva instancia de FormData
const formData = new FormData();
// Agregar el Blob al FormData con un nombre específico
formData.append("image", blob, "photo.png");
// Realizar la petición Fetch al servidor
fetch("http://127.0.0.1:5000/login", {
method: "POST",
body: formData,
})
.then((response) => response.json())
.then((data) => {
// Manejar la respuesta del servidor si es necesario
if (data.message) {
loginMsg.innerText = data.message;
loginData.innerHTML = `<b>User: </b> ${data.user}<br /><b>ID: </b>${data.id}`;
} else {
loginMsg.innerText = data.error;
}
})
.catch((error) => {
console.error("Error en la petición Fetch: ", error);
});
// Mostrar la imagen capturada en la página
const url = URL.createObjectURL(blob);
capturedImage.src = url;
capturedImage.style.display = "block";
});
});El código mencionado anteriormente se encarga de capturar el evento de clic del botón. Al hacerlo, toma una imagen desde la cámara web y la envía al servidor mediante una solicitud HTTP. Los datos se transmiten en forma de formulario multipart, ya que se trata de un archivo multimedia.
Backend
mkdir backend
cd backend
python3 -m venv virtualEnv
source virtualEnv/bin/activate
pip install face-recognition flask flask-cors
touch index.py service.py
mkdir models# index.py
from flask import Flask, request, jsonify
from flask_cors import CORS
import service
app = Flask(__name__)
CORS(app)
@app.route('/login', methods=['POST'])
def login():
image_file = request.files['image']
found_id = service.login(image_file)
if found_id is not None:
splitted = found_id.split("-")
return jsonify({'message': f'Inicio de sesión exitoso', "id": splitted[0], "user": splitted[1]})
return jsonify({'error': 'La cara no coincide con ninguna persona conocida'})En el código previo, se establece un servidor Flask junto con un punto final (endpoint) que recibe la imagen y luego invoca el servicio para su comparación posterior.
# service.py
import face_recognition
import os
def login(image_file):
models_folder = 'models/'
known_faces = {}
for file_name in os.listdir(models_folder):
if file_name.endswith('.png'):
image_path = os.path.join(models_folder, file_name)
image = face_recognition.load_image_file(image_path)
face_encoding = face_recognition.face_encodings(image)[0]
person_id, _ = os.path.splitext(file_name)
known_faces[person_id] = face_encoding
unknown_image = face_recognition.load_image_file(image_file)
unknown_face_encoding = face_recognition.face_encodings(unknown_image)
# Si no se encuentra ninguna cara en la imagen enviada
if len(unknown_face_encoding) == 0:
return None
unknown_face_encoding = unknown_face_encoding[0]
# Comparar con las caras conocidas
found_id = None
for person_id, face_encoding in known_faces.items():
# Comparar las caras
matches = face_recognition.compare_faces([face_encoding], unknown_face_encoding)
if matches[0]:
found_id = person_id
break
return found_idEn este fragmento de código, se compara la imagen recibida como parámetro con las fotografías almacenadas actualmente en la carpeta “models/“. Si se encuentran coincidencias, se devuelve el nombre del archivo correspondiente.
Finalmente, ejecutamos el proyecto
flask --app index runAhora debe estar disponible en el puerto 5000 así: http://localhost:5000
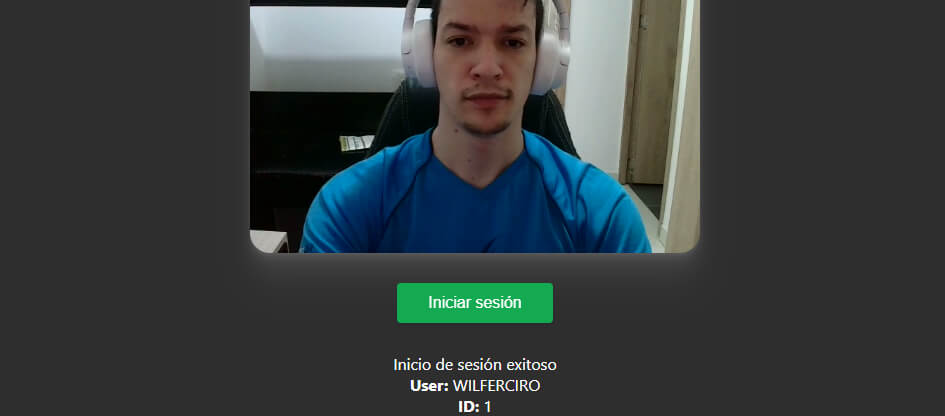
Lo único que resta por hacer es agregar las imágenes de muestra a la carpeta “models/“. En esa carpeta, se deben incluir diversas imágenes de diferentes personas con el formato: ID-NOMBRE.png. Posteriormente, abrimos nuestro archivo HTML, permitimos el acceso a la cámara y ¡listo! Todo debería funcionar correctamente.
¿Qué sigue?
El sistema actual es básico, sirviendo solo como demostración de un servidor Flask y la biblioteca face_recognition para un inicio de sesión simple. Para mejorarlo, se deben añadir comprobaciones de bases de datos, implementar sistemas de autenticación como JWT, incorporar lógica JavaScript para una experiencia de usuario mejorada y ejecutarlo en un contenedor Docker para facilitar su implementación en la nube.